为什么C++要比Java和Python快??🤪
- 有的编程语言要求必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序(比如 Windows 下的 .exe 文件),比如C语言、C++、Golang、汇编语言等,它们都属于编译型语言,使用的转换工具称为编译器。
- 有的编程语言可以一边执行一边转换,需要哪些源代码就转换哪些源代码,不会生成可执行程序,比如 Python、JavaScript、PHP、Shell 等,这类编程语言称为解释型语言,使用的转换工具称为解释器。
编译型语言
对于编译型语言,开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件就是一个可执行程序,它里面包含的就是机器码,只要拥有这个可执行程序,就可以随时运行,不需要再重新编译,也就是“一次编译,无限次运行”。
在运行的时候,我们只需要编译生成的可执行程序,此时就不再需要源代码和编译器,所以编译型语言可以脱离开发环境运行。
编译型语言通常是不能跨平台的,也就是不能在不同的操作系统之间随意切换。
编译型语言不能跨平台表现在两个方面:
1) 可执行程序不能跨平台
可执行程序不能跨平台很容易理解,因为不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间也不能兼容。不能跨平台是天经地义,能跨平台反而才是奇葩。
比如,你不能将 Windows 下的可执行程序拿到 Linux 下使用,也不能将 Linux 下的可执行程序拿到 macOS 下使用(虽然它们都是类 Unix 系统)。
注意:相同操作系统的不同版本之间也不一定兼容,比如不能将 x64 程序(Windows 64 位程序)拿到 x86 平台上(Windows 32 位平台)运行。但反之一般可行,因为 64 位 Windows 对 32 位程序做了很好的兼容性处理。
2) 源代码不能跨平台
不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台直接运行。下面以C语言为例进行说明。
【实例1】在C语言中,要想让程序暂停,我们可以使用“睡眠”函数。在 Windows 平台下该函数是 Sleep() ,并以毫秒为时间单位,而在 Linux 平台下则是 sleep(), 以秒为单位。可以看出,首先两个函数的首字母大小写不同,再者 Sleep() 的参数是毫秒,而 sleep() 的参数是秒,单位也不一样。
以上两个原因导致具有暂停功能的C语言程序不能跨平台,除非在代码层面对平台的兼容性做出处理,但这非常麻烦。
【实例2】虽然不同平台的C语言都支持 long 类型,但不同平台下 long 类型所占用的字节长度却不相同。例如 Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 却占用 8 个字节。
如果在 Linux 64 位平台下编写代码时,将 8 字节的值赋值给 long 类型的变量,这是完全没有问题的,但如果是在 Windows 平台下就会导致数值溢出,让程序产生错误的运行结果。
解释型语言
对于解释型语言,每次执行程序都需要一边转换一边执行,用到哪些源代码就将哪些源代码转换成机器码,用不到的则不进行任何处理。
由于每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至是数量级的差距。因此计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
在运行解释型语言的时候,我们始终都需要源代码和解释器,所以说它无法脱离开发环境。
例如,当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义:
- 对于编译型语言,我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的;
- 对于解释型语言,我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
相比于编译型语言,解释型语言几乎都能跨平台,“一次编写,到处运行”是真实存在的,而且比比皆是。那么,为什么解释型语言就能跨平台呢?
其实,这一切都要归功于解释器!
这里所说的跨平台,是指源代码跨平台,而非解释器跨平台。解释器用来将源代码转换成机器码,它本质上就是一个可执行程序,是绝对不能跨平台的。
说白了编译型语言在编译之后拿着.exe文件,不管在哪都能跑,不用配置环境什么的,,而解释型就不行了,要运行就得配置环境(python解释器,,java解释器,虚拟机)
C++ 编译流程
C++ 程序在编写完成或者做了更改后的第一次运行前,需要先编译。C++ 编译的整个过程分为 4 步:
注意在汇编前的程序都是文本,经过汇编,就转换为了二进制文件,C++ 中常说的机器码就是二进制,二进制文件就可以直接交由计算机运行了。接下来详细讲一下四个步骤中发生了什么:
- 预处理
在预处理阶段,比如我们现在写了一个 main.cpp 文件进行预处理。预处理器会将头文件导入当前的代码,比如 iostream 或 string 等头文件。
之后会将注释给删除,将代码中的宏替换为宏的定义。
预处理直接对源文件进行处理,并不关注语法规则等,处理后的文件为 main.i。 - 编译
在编译阶段,编译器会检查代码的语法是否正确,并且可以对代码进行优化(O1,O2 优化等),之后将 main.i 文件转换为汇编语言程序 main.s,汇编语言是一种相对底层的语言,它为各种不同的高级语言提供了统一的输出(JAVA,C/C++ 等) - 汇编
在汇编阶段,汇编器将 main.s 汇编语言文件转换为机器语言指令(也就是常说的二进制机器码),并将文件转换为 main.o。这时候如果用文本打开该文件,会得到一堆乱码,这是因为文本编辑器通常使用 UTF-8 的 ASCII 码进行编解码,而这些二进制文件是不适用的。 - 链接
在链接阶段,链接器会将上述的 main.o 文件与库文件(后缀为 .a 或者 .lib)链接为一个应用程序,我们可以在执行链接时指定需要使用的库。
链接分为静态链接和动态链接,静态链接就是简单地将所需要链接的库的内容全部加入目标可执行程序中。静态链接的问题在于在一个计算机中如果存在多个相同程序,那么这些程序都会拷贝这个静态库,相当于内存中会存在多份静态库的拷贝,相当占用内存!另外,静态库对程序的更新会带来麻烦,如果静态库更新了,所有使用它的应用程序都需要重新编译再发布给用户。
而与之相对的是动态链接,动态链接不会讲库拷贝到程序中,而是在应用程序中添加所调用库的描述信息(一般是库函数的重定位信息),执行的时候就会根据库的重定位信息调用库函数。所以动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库更新时带来的麻烦。用户只需在运行程序时更新动态库即可。 - 应用程序包含的是机器码,也就是二进制数据,这些二进制指令是可以直接交由计算机操作的,是一种最底层语言,因此效率很高。而且多次执行相同的程序,只有第一次需要编译。
Python 代码执行流程
Python 之所以被称为脚本语言,是因为其不需要在运行前编译,而是在运行过程中“像脚本一样”被解释器逐句转换为机器码(二进制),这样的话相当于每次执行 Python 脚本,都要再进行一次转换为二进制的过程,因此在这一点上 Python 就已经慢了很多。
C++ 与 Python 效率比较
言归正传,所以这两种语言的效率差异到底体现在什么地方呢?
首先第一点就是上文提到的,每次执行 Python 脚本,都要再由解释器进行一次转换为二进制的过程,而 C++ 只有第一次需要编译,后续都可以直接执行机器码。
这里我们可以举一个例子:
编写 Python 脚本时不需要声明类型,而是交由解释器进行动态类型检查。Python 官方指定的解释器为 CPython,CPython 是基于 C 实现的,在 CPython 中,每个对象底层都是一个 Obj* 指针类型,这个指针可以指向任意一种类型,所以所以它可以指向任意的对象,因此Python无法做基于类型方面的优化。以变量a + b为例,这个a和b指向的对象可以是整型、浮点型、字符串、列表、元组、甚至是我们自己实现了某个方法的类的实例对象。在计算 a+b 时,首先 Python 要判断变量到底指向的是什么类型,这在 C 级至少需要一次属性查找。然后 Python 将每一个操作都抽象成了一个方法,所以实例相加时要在对应的类型对象中找到该方法对应的函数指针,这又是一次属性查找。找到了之后将a、b作为参数传递进去,这会发生一次函数调用,会将 a 和 b 中维护的值拿出来进行运算,然后根据相加结果创建一个新的对象,再返回其对应的 PyObject * 指针。而对于 C++ 来讲,由于已经规定好了类型,所以a + b在编译之后就是一条简单的机器指令,所以两者在效率上差别很大。
第二点是 C++ 在编译阶段是可以进行优化的,C++ 编译器通常默认是 O0 优化,这是使用了最快的编译时间,在这种优化模式下:
所有变量都存在内存中,只有运算结果会放在 CPU 的寄存器上,所以会有较多的内存读写操作。
禁用其他的优化,会尽可能按照用户代码生成指令。
O1 优化:
循环变量通过寄存器计算,不再写入内存(比如 for (int i = 0; i < 10; ++i) 中的 i)
之后还有 O2 和 O3 优化,但是因为这些优化比较激进,会大幅增加编译的时间,而且编译后的文件难以调试,一般比较少用到。
总之,C++ 中存在编译过程的优化,而 Python 并没有,这又在另一个维度上让 C++ 快于 Python。
Java语言是编译型语言还是解释型语言?
我们都知道,编程语言从程序执行过程分,分为编译型语言和解释性语言
什么是编译型语言和解释型语言?
Java语言看似是编译型的,因为Java程序代码的确是需要经过编译的
还记得在cmd中用javac的命令吗?
没错,javac就是用来编译Java程序代码的(把.java源程序编译为.class文件)
不经过编译,.java文件运行不了!
Java语言又看似是解释型的,因为Java程序要在JVM上解释运行
那到底Java是什么类型的语言呢?
==Java是解释型语言==
为什么Java是解释型语言?
Java首先由编译器编译成.class类型的文件,这个是java自己类型的文件 然后在通过虚拟机(JVM)从.class文件中读一行解释执行一行,所以他是解释型的语言,正是由于java在JVM(虚拟机)上解释运行,对于多种不同的操作系统有不同的JVM,所以 Java才实现了真正意义上的跨平台!
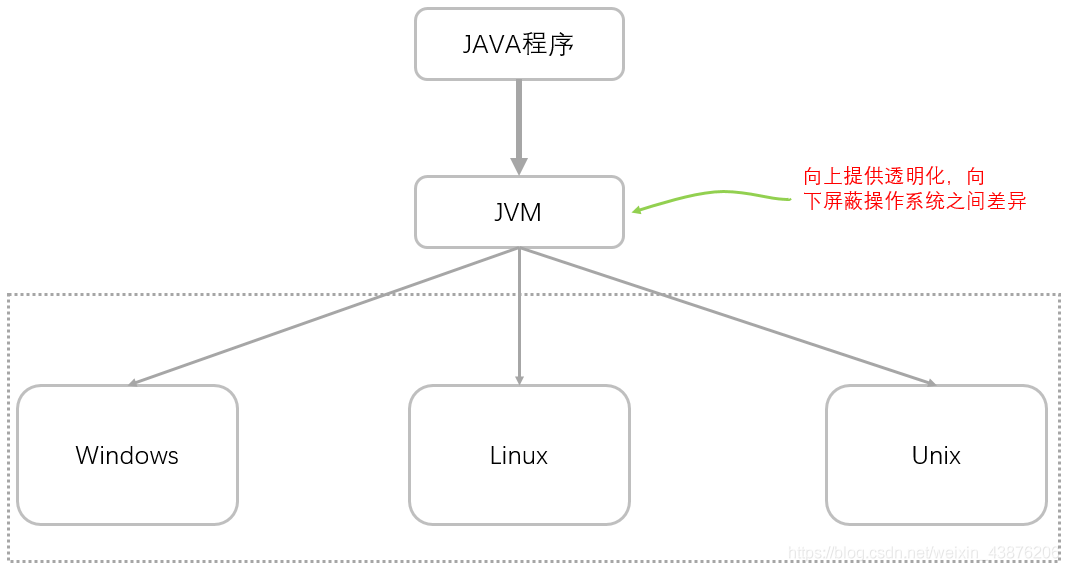
再来几张图帮助理解Java的解释执行过程:

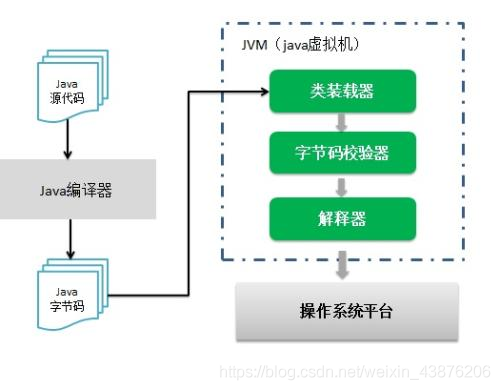
通过以上介绍,我们对Java程序执行过程就清楚了